XML 이란
XML은 확장성 마크업 언어(Extensible Markup Language)의 약자로 W3C에서 개발된, 특수한 목적들을 갖는 마크업 언어를 만드는 데 사용하도록 권장되는 마크업 언어이다
HTML과 유사한 형태를 띄고, Tag를 사용자가 정의할 수 있다
Tag는 <title>XML</title> <slide>Introduction</slide>와 같이 여는 태그가 있으면 닫는 태그가 반드시 존재한다
이러한 XML은 문서 만드는 것뿐만 아니라 데이터를 교환하는 좋은 방법이 될 수 있다
장점
- 데이터 교환 형식으로 관계형 튜플(Relational tuple) 보다 우수하다
- 태그의 존재로 자체 문서화가 가능하다(사람이 직접 데이터를 읽기 쉬움)
- 중첩 구조(Nested structure)를 허용한다
- 폭넓은 수용능력을 가졌다(ex 데이터베이스 시스템, 브라우저, 도구 및 응용 프로그램)
단점
- 스키마 정보를 나타내는 태그가 반복된다(배열구조, 반복구조일 경우 불필요한 데이터가 계속 나타난다)
XML 데이터의 구조(Structure of XML Data)
Tag(태그) : 태그라는 마크업 기호를 사용해서 데이터를 정의한다 ex) 서점에 대한 데이터를 나타낼 때 <book>, <title> 및 <author>과 같은 태그를 만들 수 있다
Element(요소) : 여는 태그와 닫는 태그로 구성된다
알맞은 예 <course>...<title> ... </title></course>
틀린 예 <course>...<title> ... </course></title>

Attributes(속성) : 요소는 속성을 가질 수 있다
ex) <course course_id = "CS-101">
- 속성(Attribute)은 요소(Element)의 시작 태그(Starting tag) 안에 한쌍의 name=value 형식으로 지정된다
- 요소는 여러게의 속성을 가질 수도 있는데, 속성의 이름은 중복될 수 없다
Attributes(속성)과 Subelements(하위 요소)의 구분
문서의 맥락에서 속성은 마크업에 일부이고 하위 요소 내용은 기본 문서 내용의 일부이다
- Attribute(속성) : <course course_id= "CS-101">...</course>
- Subelement(하위 요소) : <course><course_id> CS-101 <course_id>.... </course>
추천하는 방법은 요소의 식별자에는 속성을 사용하고, 콘텐츠에는 하위 요소를 사용하는 것이다
XML Namespace(네임스페이스)
- XML 네임스페이스는 XML 요소 간의 이름에 대한 충돌을 방지해 주는 방법을 제공한다
- 동일한 태그는 조직마다 다른 의미를 가질 수 있는데, 이것은 교환된 문서 간에 혼동을 줄 수 있다
- XML 네임스페이스는 요소의 이름과 속성의 이름을 하나의 그룹으로 묶어서 이름에 대한 충돌을 해결한다

Fig. 2 그림과 같이 예제 1의 <body> 요소는 HTML 문서의 <body> 태그인 반면 예제 2는 각 신체 부위의 치수를 기록하기 위해 사용되었습니다
하지만 이런 충돌을 방지해주는 것이 Namespace인데,

Fig. 3의 예시와 같이 University 요소의 xmlns 속성은 yale:이라는 접두사를 선언한다
이렇게 XML 요소에 네임스페이스가 선언되면, 해당 요소의 모든 자식(child) 요소에도 같은 네임스페이스가 선언된다
XML Document Schema(XML 문서 스키마)
데이터베이스 스키마는 데이터베이스의 구조와 제약조건에 관해 전반적으로 기술한 것을 말한다
XML 문서는 스키마와 관련된 것을 요구하지 않는다
하지만 XML 데이터 교환할 때, 스키마는 중요합니다
그렇지 않으면 다른 사이트에서 받은 데이터를 자동으로 해석할 수 없다
그래서 두 가지의 XML 스키마 구조 있는데, Document Type Definintion(DTD) 그리고 XML Schema이다
Document Type Definition(DTD)
XML 문서 유형은 DTD를 사용해서 지정할 수 있다(문서의 구조를 정의하는 규칙의 집합)
XML 데이터의 DTD 제약 구조
- 발생할 수 있는 요소(Element)
- 요소가 가질 수 있는/가져야 하는 필수 속성
- 각 요소 내에서 발생할 수 있는/발생해야 하는 하위 요소 및 발생 횟수
DTD는 데이터 타입을 제한하지 않는다
모든 값이 스트링 타입으로 XML에 나타난다
DTD로 선언
1) 요소(elements)
XML 문서에서 사용할 수 있는 요소 이름, 요소 간의 계층 구조 정의
하위 요소는 다음과 같이 지정할 수 있다
- #PCDATA(parsed character data) i.e., character strings, or
- EMPTY(하위 요소가 없다(no subelements)) or ANY (무엇이든지 하위요소가 될 수 있다 anything can be a subelement)
ex)
<! ELEMENT department (dept_name, building, budget)>
<! ELEMENT dept_name (#PCDATA)>
<!ELEMENT budget (#PCDATA)>
다음과 같은 정규 표현(regular expressions)이 있다
<!ELEMENT university ((department | course | instructor | teaches)+)>
기호
- "|" - 자식 요소를 선택해서 가진다
- "?" - 자식요소를 가지지 않거나, 하나의 자식 요소만을 가진다
- "*" - 자식요소를 가질 수도 있고, 가지지 않을 수도 있다
- "+" - 최소한 하나 이상의 자식 요소를 가진다
2) 속성(Attributes)
요소에 추가되는 속성, 값의 범위, 필수적인 속성 여부 정의
속성의 타입
- CDATA (속성의 데이터 타입)
- ID(식별자(identifier)) or IDREF(ID 참조(reference)) or IDREFS(multiple IDREFs)
속성 기본 값
- #REQUIRED - 속성 값을 반드시 명시적으로 사용
- #IMPLIED - 속성 값을 선택적으로 사용. 속성을 명시할 수도, 하지 않을 수도 있다
예시

DTD의 제한사항
- 제한된 자료형
- 순서가 지정되지 않은 하위 요소 집합을 지정하기 어렵다
XML Schema(스키마)
XML Schema는 DTD의 단점을 해결하는 또 다른 XML 구조입니다
- 데이터 타입에서 자유롭다(Integer, string, etc), 또한 최소/최대(min/max)에 대한 제약 조건
- Namespace 권고안을 지원한다
쿼리와 XML 데이터 변환은 밀접한 관련이 있으며, 같은 도구들의 집합에 의해 처리된다
- XPath - 경로 표현식으로 구성된 단순 언어
- XSLT - XML에서 XML로, XML에서 HTML로 변환하기 위해 설계된 간단한 언어
- XQuery - 풍부한 기능 집합이 있는 XML 쿼리 언어
쿼리 그리고 언어 변환(Transformation language)은 XML 데이터의 Tree model의 기반으로 되어있다XML 문서는 Tree 형식처럼 되어있고, 요소와 속성은 Tree에서 node와 일치한다
XML 데이터는 Flat files 혹은 XML 데이터베이스에 저장됩니다
- Flat file - 일반적인 저장
- XML 데이터베이스 - 데이터 저장을 위해 특별히 제작된 데이터베이스로 DOM 모델 및 선언적 쿼리를 지원
데이터는 반드시 관계형(Relational form)으로 번역되어야 한다
String Representation
관계형 데이터베이스에서 각 최상위 요소를 튜플의 문자열 필드로 저장
단일 관계를 사용하여 모든 요소를 저장하거나, 각 최상위 요소 유형에 대해 별도의 관계 사용한다
ex) account, customer, depositor relations
인덱싱(Indexing)
관계에 추가 필드로 인덱싱할 하위 요소/속성 값 저장 및 이 필드에 인덱스 작성
ex) customer_name or account_number
장점
- DTD 없이 모든 XML 데이터 저장 가능
- 개별 요소에 빠르게 접근할 수 있다
단점
- 요소 내부의 값에 액세스 하려면 문자열을 구문 분석해야 한다
- 구문 분석이 느리다
Tree Representation
관계를 사용하여 XML 데이터를 트리 및 저장소로 모델링
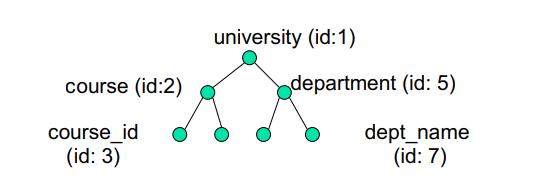
- 각 요소/속성에는 고유 식별자(identifier)가 부여된다
- 타입(type)은 요소/속성을 나타낸다
- Label은 요소의 태그 이름/속 석의 이름을 지정한다
- Value는 요소/속성의 텍스트 값이다
- 하위 항목의 순서를 기록하기 위해 추가 속성 위치(extra attribute position)를 추가할 수 있다
장점
- DTD 없이도 모든 XML 데이터 저장 가능
단점
- 데이터가 너무 많은 조각으로 분할되어 공간 오버헤드 증가
- 단순 쿼리에도 많은 조인이 필요해서 속도 감소
Mapping XML Data to Relations
각 요소 type에 따라 생성된 릴레이션 :
- 각 요소의 고유 ID를 저장하는 ID 속성
- 각 요소 속성에 해당하는 관계 속성
- 상위 요소를 추적하는 parent_id 특성
한 번만 발생하는 모든 하위 요소는 관계 속성이 될 수 있습니다
- 텍스트 값 하위 요소의 경우 텍스트를 속성 값으로 저장
- 복잡한 하위 요소의 경우 하위 요소의 ID를 저장
여러 번 발생할 수 있는 하위 요소는 별도의 표에 표시됩니다
- ER 다이어그램을 표로 변환할 때 다중 값 속성 처리와 유사하다
Application Program Interface(파싱 방법)
XML 데이터에 대한 두 가지 표준 파싱 방법이 있습니다
- SAX(Simple API for XML)
SAX 방식은 라인을 하나하나 순차적으로 읽어가며 파싱을 수행한다
- DOM(Document Object Model)
DOM방식은 메모리에 모두 로드를 한 후 파싱 한다
메모리에 모두 로드(Load)되어 있기 때문에 검색, 수정 등 방식이 빠르고, SAX보다 파싱 하기 용이하다
장단점
DOM 방식은 메모리에 올려둔 후 처리를 하기 때문에 메모리에 올리는 과정이 별도로 들어가게 되지만, XML을 여러 번 핸들링해야 할 경우, DOM 방식은 SAX보다 유리하다
반대로, SAX는 한번 읽고 나서 끝이라고 생각하면 이해가 쉽다. DOM처럼 전체를 메모리에 올리지 않기 때문에 메모리의 사용량이 적으며, 별도의 작업이 추가적으로 들어가지 않는다
- XML 문서를 수정, 핸들링 작업 -> DOM
- 단순히 데이터 파지, 화면에 View -> SAX
- 대용량의 데이터로 인해서, 메모리 문제가 발생하면 -> SAX
- XML 구조 복잡 -> DOM
- 단순하게 설정을 읽는 경우 -> SAX
XPath
XPath란 XML Path Language를 의미합니다.
XPath는 XML 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어입니다
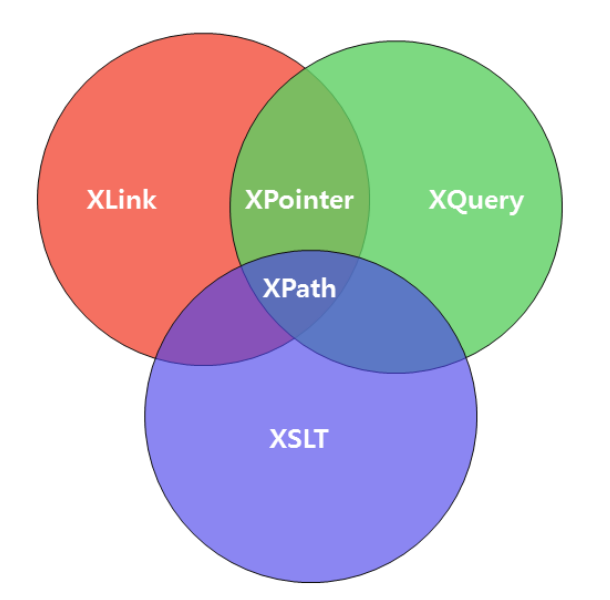
XPath는 W3C 표준 권고안으로, XSLT와 XPointer에 사용될 목적으로 만들어졌습니다
또한, XML DOM에서 노드를 검색할 때에도 사용할 수 있습니다
XPath 특징
1. XPath는 XML 문서를 탐색하기 위해 경로 표현식(path expression)을 사용합니다
2. XPath는 수학, 문자열 처리 등을 하기 위한 표준 함수 라이브러리를 내장하고 있습니다
3. XPath는 W3C의 표준 권고안인 XSLT에서 가장 중요한 부분 중 하나입니다
XSLT
XML 문서는 다양한 장치에서 데이터를 저장하고 전달할 목적으로 만들어졌습니다.
하지만 각각의 장치는 내부적으로 자신만의 고유한 데이터 구조를 사용하고 있습니다.
따라서 각각의 장치가 전달받은 XML 문서를 자신이 사용하는 데이터 구조로 변환할 때 사용할 규칙이 필요합니다
이러한 변환 규칙에 대한 명세를 작성할 수 있는 언어가 바로 XSL(eXtensible Stylesheet Language)입니다
CSS가 HTML 문서를 위한 스타일 시트 언어라면, XSL은 XML 문서를 위한 스타일 시트 언어입니다
구성
XSL은 XML 문서의 변환과 표현을 정의하는 세 개의 언어로 구성됩니다
1. XSLT : XSL Transformations를 의미하며, XML 문서를 다른 구조의 문서로 변환시키기 위한 언어입니다
2. XPath : XML 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어입니다
3. XSL-FO : XML 데이터를 출력하기 위한 목적으로 설계된 언어입니다
XQuery
XQuery는 XML 데이터를 쿼리하고 수정하는 데 필요한 특정 요구사항을 충족시키기 위해 W3C(World Wide Web Consortium)에서 설계한 함수 프로그래밍 언어입니다.
예측 가능하고 일반 구조로 이루어진 관계형 데이터와 달리, XML 데이터는 매우 다양합니다. XML 데이터는 예상할 수 없는 경우가 많고, 희소하며, 자기 설명적입니다.
XML 데이터의 구조를 예상할 수 없기 때문에 XML 데이터에 대해 수행해야 하는 쿼리는 종종 일반 관계형 쿼리와 다릅니다. XQuery 언어는 이러한 종류의 조작을 수행하는 데 필요한 유연성을 제공합니다. 예를 들어, XQuery 언어를 사용하여 다음 조작을 수행해야 합니다.
- 알 수 없는 계층 구조 레벨에 있는 오브젝트에 대해 XML 데이터를 검색합니다
- 데이터에 대해 구조적 변환을 수행합니다(예: 계층 구조를 역전시키기)
- 혼합 유형의 결과를 리턴합니다
- 기존 XML 데이터를 갱신합니다
Reference
http://www.tcpschool.com/xml/xml_basic_namespace
코딩교육 티씨피스쿨
4차산업혁명, 코딩교육, 소프트웨어교육, 코딩기초, SW코딩, 기초코딩부터 자바 파이썬 등
tcpschool.com
https://needjarvis.tistory.com/32
XML과 DOM, SAX 방식
현재의 웹 생태계는 어느덧, API를 웹상으로 호출하는 방식의 시대로 패러다임이 변화하고 있다. 정부 3.0의 정부 데이터를 공개를 시작으로 SECaaS, OPEN API, 기타 서비스 클라우드를 콜하는 것까지
needjarvis.tistory.com
https://www.ibm.com/docs/ko/db2/11.1?topic=purexml-querying-xml-data